Branching with Redgate SQL Source Control
A couple of years ago my team and I decided to change the name of a column in a loan origination system. 99% of the time this was no big deal. However, this was the primary key identity column used to uniquely identify a loan in the application. Renaming a column is rather easy using T-SQL, just run sp_rename stored procedure. It takes less than 30 seconds to write out the whole script. The code, on the other hand, was not as easy. We did a find and replace in the source code, but then we had to wait for the build process to run through and push up all the code. The developer who ran the rename stored procedure was not the developer who changed the code. They didn't coordinate their efforts as best they could and as a result, our team was down for about an hour or so while this was changed.
One of the big reasons to automate database deployments is to treat database changes just like source code changes and avoid situations like that. They are packaged up and deployed through the environments. Both the code changes and the database changes should have been pushed at the same time and deployed within 30 seconds of one another in an automated fashion.
Now let's say it took the developer multiple days to change over all the code. One of the major advantages source code has had since the dawn of well, any version control system, is branching. The developer could create a branch, make all the changes they could for the day, and push up the branch at the end of the day. To help out, other developers could also checkout that branch and make changes. The only kicker was the database. Prior to adopting a tool such as Redgate's SQL Source Control, it was not very easy to branch the database. A manual process using scripts or another Redgate tool, SQL Compare, would be most likely be used. Manual steps are bad. They are forgotten.
A branching strategy is important because it allows developers on the team to make changes without affecting everyone else. In addition, it allows developers to follow rule #1 when it comes to continuous delivery, the master or main branch must be able to be deployed to production at any time. That is just not possible without branching unless your project is very simple with only one or two developers.
However, it is not as simple as it sounds when put into practice. The purpose of this article is to walk through some of the more common issues with branching a database.
Please Note: It is highly recommended the dedicated database model is selected in SQL Source Control. A shared database model means every developer shares the same database, which essentially means, the database will most likely match the main or master branch. When using a dedicated database each developer is free to create branches and experiment in the database without fear of affecting others.
Version Control Options
This article will cover both Team Foundation Version Control (TFVC) and GIT. I chose these two because of most version control systems because they represent the two more common version control mechanisms, centralized and distributed.
TFVC - Centralized: With centralized version control systems there is a single central version of the source control, typically stored on a server. When a developer checks in changes they visible right away to all the other developers.
When a user creates a branch it is immediately created on the server and on every user's workspace. In TFVC, branches are stored within the same repository and can be viewed at any time. This is easily visualized via the Visual Studio source control explorer.
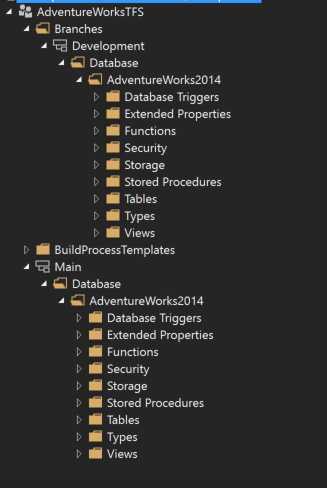
As you can see each branch is a full copy. What this means is the folder structure typically looks like this:
GIT - Distributed: Distributed version control systems don't have to rely on a single server to store the history of the project. Instead, each developer has a copy, or clone, of the entire repository on their machine. Unlike centralized version control, a developer can check in multiple times and other developers won't see those check-ins until the developer pushes their changes to a common location. Then each developer pulls down the latest changes onto their copy.
When a developer creates a branch it is not visible to other developers until they push that branch. This allows for experimentation because a developer can create a branch, make some changes, realize they suck, and then delete the branch. In TFVC, the entire folder structure, including all branches, could be viewed using a windows explorer. In GIT, this is not possible, a developer can only view a single branch at a time when looking at the folder in windows explorer. A developer checks out a branch, which swaps all the files. It makes more sense when looking at it through screen shots.
The main branch looks like this:
The development branch looks like this (exactly the same):
GIT Database Branching
GIT presents an interesting opportunity when it comes to branches due to the fact only one branch is viewable through windows explorer at a time. This makes it possible to use a single database for all the branches. When the developer switches between branches SQL Source Control will pick up on the difference and show what needs to be changed in the get latest tab. When using TFVC, the developer had to unlink and relink if they wanted to use a single database. When using GIT, there is no need to do that. That makes the workflow a little simpler.
- Commit all pending changes to main branch
- Checkout (or switch) to development branch
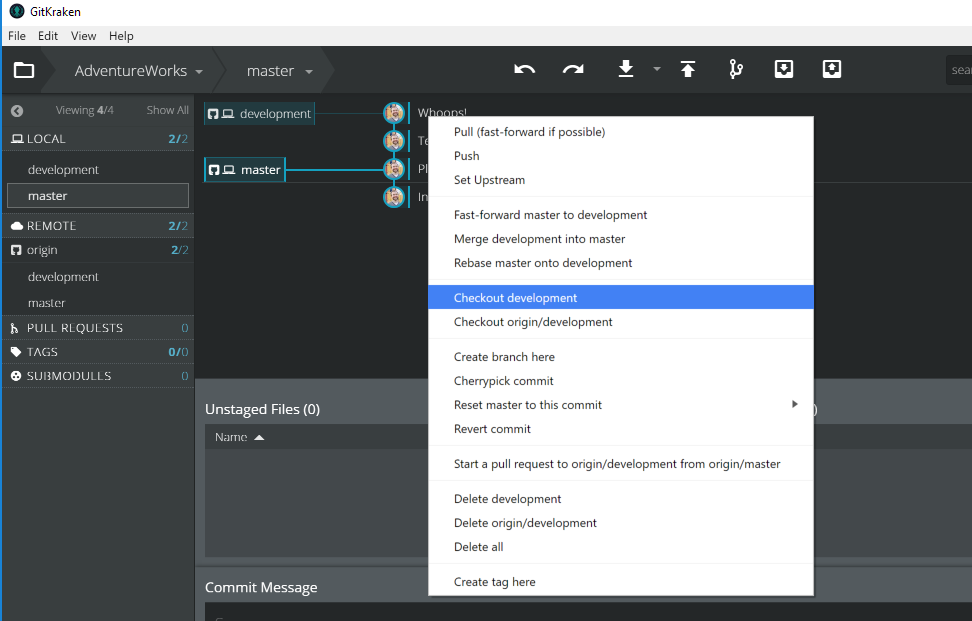
- Get latest changes from development
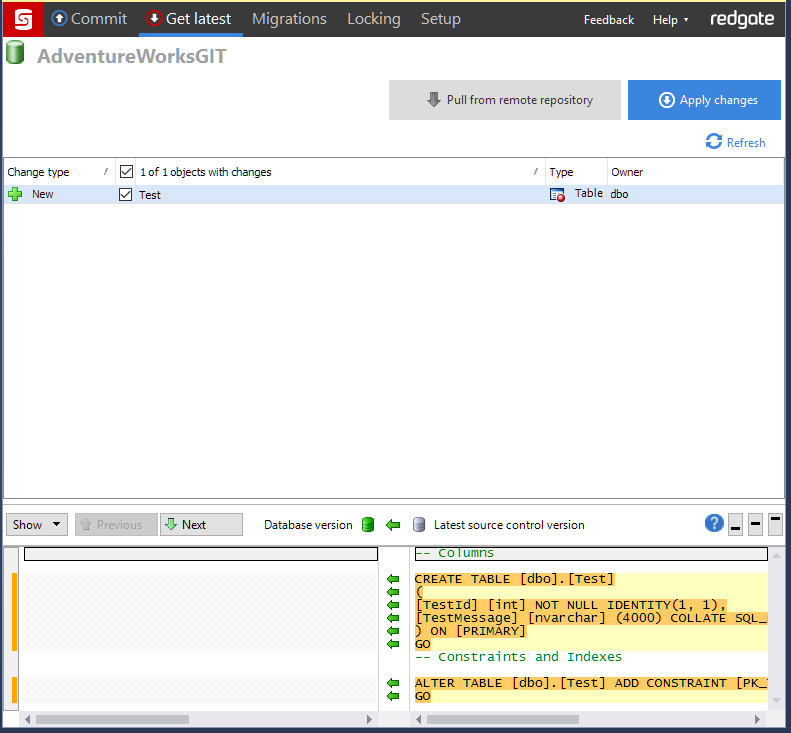
- Make changes to database
- Commit all pending changes to development branch
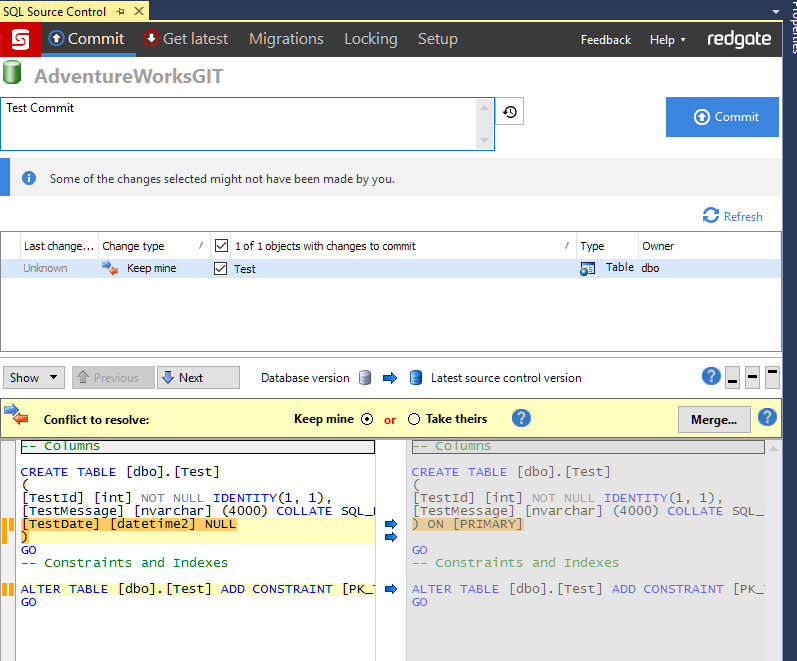
- Checkout (or switch) to master or main branch
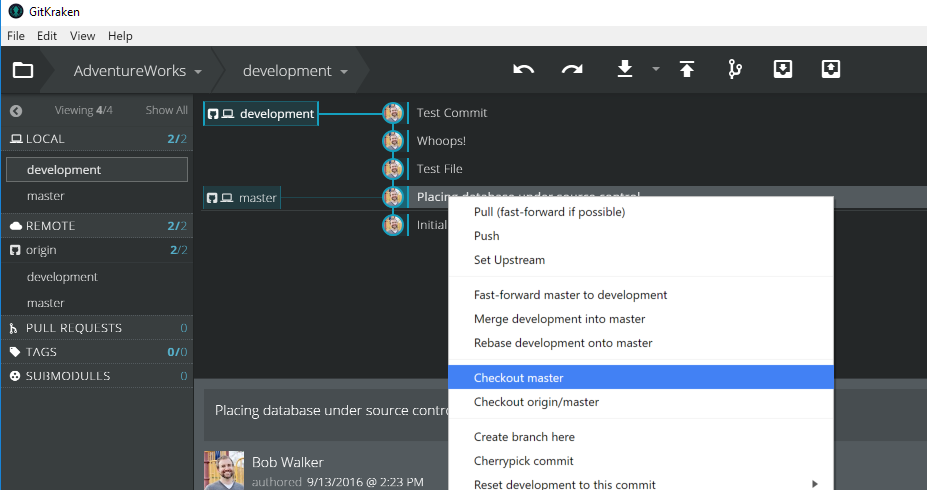
- Get latest changes, which will wipe out any changes from development.
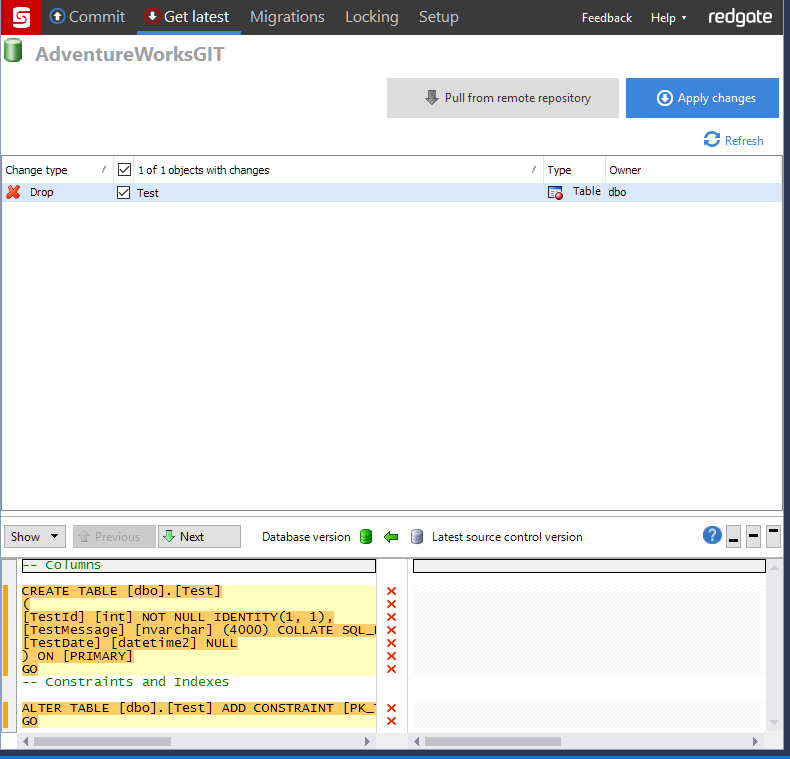
This is actually what I use day to day with GIT. It works out pretty well but there are a few caveats.
Database Thrashing
There could be a lot of thrashing, depending on the delta between development and master. Right now we have a new table in development but not in master. Each time I switch branches I am either adding the table or deleting the table. Because I am the only one connecting to the database it is not a big deal. It only becomes a real pain when data is needed in that table for certain functionality. The thrashing will increase as the delta grows between development and master. Eventually, a point will be reached where it is just not worth the effort. At that point, it makes sense to create a separate database for development until development can be merged into master.
Easy to forget to get latest
I tend to forget at least once a week to go into SQL Source Control and get latest when I switch between branches. It only takes a failing automated test or some sort of code randomly blowing up for me to remember. But still, it is a bit of a hassle.
TFVC Database Branching
One of the first questions that should be asked when establishing a branching strategy with the database is, will each branch get a copy of the database? When thinking through it for TFVC, it makes sense. Let's look at the folder structure if you have a simple development/main branching strategy.
- Root folder
- BuildProcessTemplates
- Main
- Database
- AdventureWorks2014
- Database
- Branches
- Development
- Database
- AdventureWorks2014
- Database
- Development
There are two database folders in this example. It is possible to use a single database. But the workflow is a bit wonky to use a single database when switching between branches.
- Commit all pending changes to main branch
- Unlink database from source control
- Link database to source control, but link it to development branch
- Get latest changes from development
- Make changes to database
- Commit all pending changes to development branch
- Unlink database from source control
- Link database to source control, but link it to master or main branch
- Get latest changes, which will wipe out any changes from development.
With TFVC it makes a lot more sense to have multiple databases, one for each branch. It is rather easy to do. Create one database and point it to the development branch.
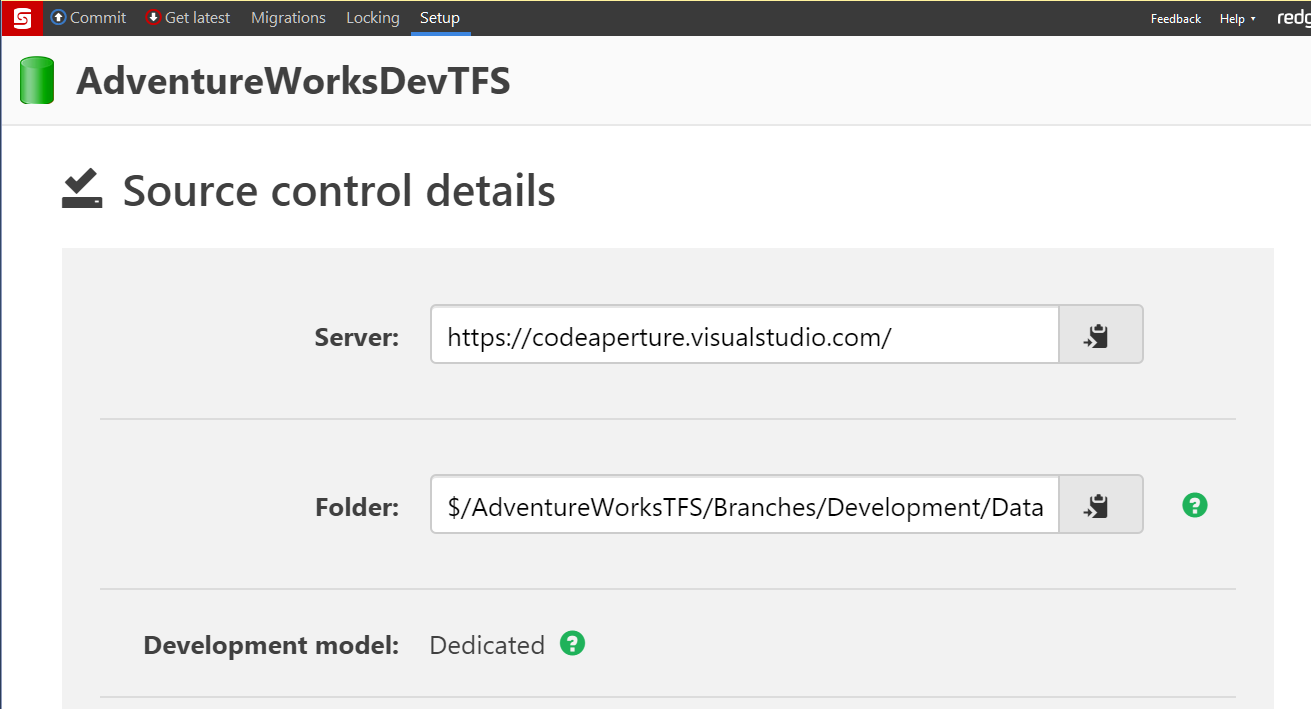
And another database and point it to the main branch.
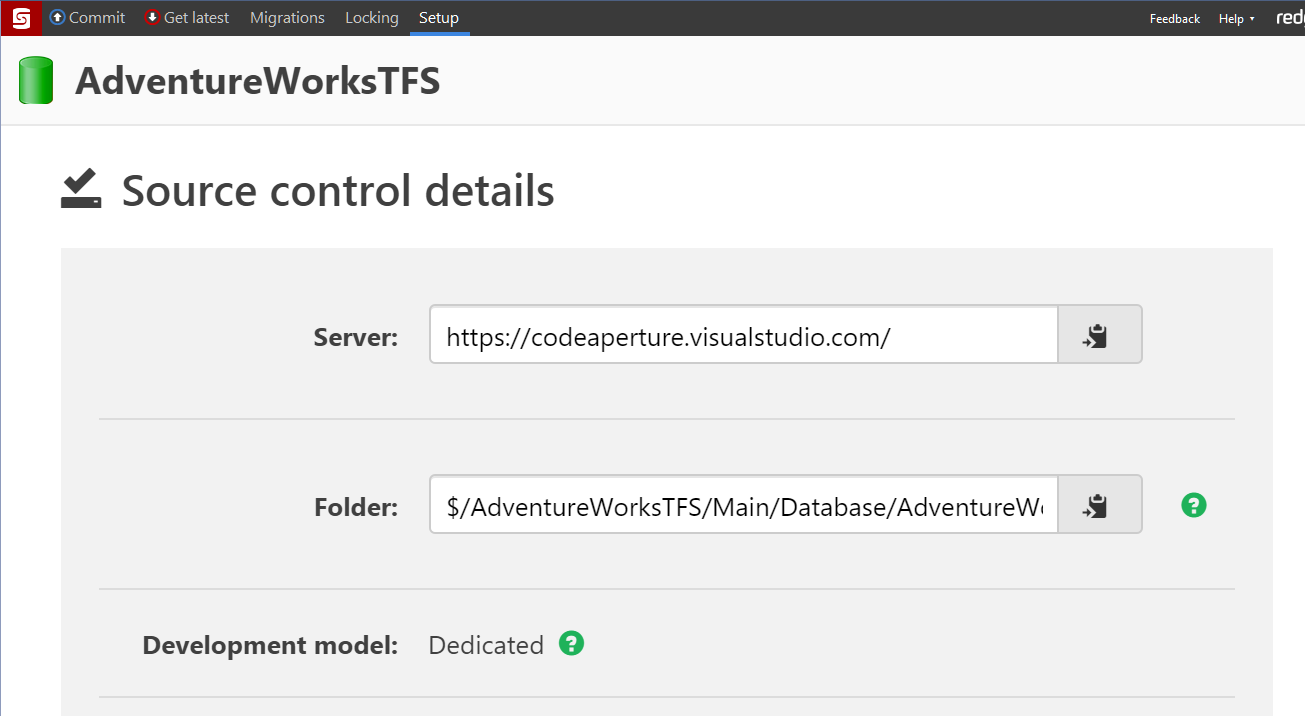
That being said, it is not a magic, cure-all, solution. What happens when a branch is created from development, or a branch is created from main? The easiest would be to use the same database as before, use the development database if the branch was created from development, use the main database if the branch was created from main. Only look into spinning up a new database for the branch if is absolutely needed. Keep it simple to start, it is always easy to make it more complicated later.
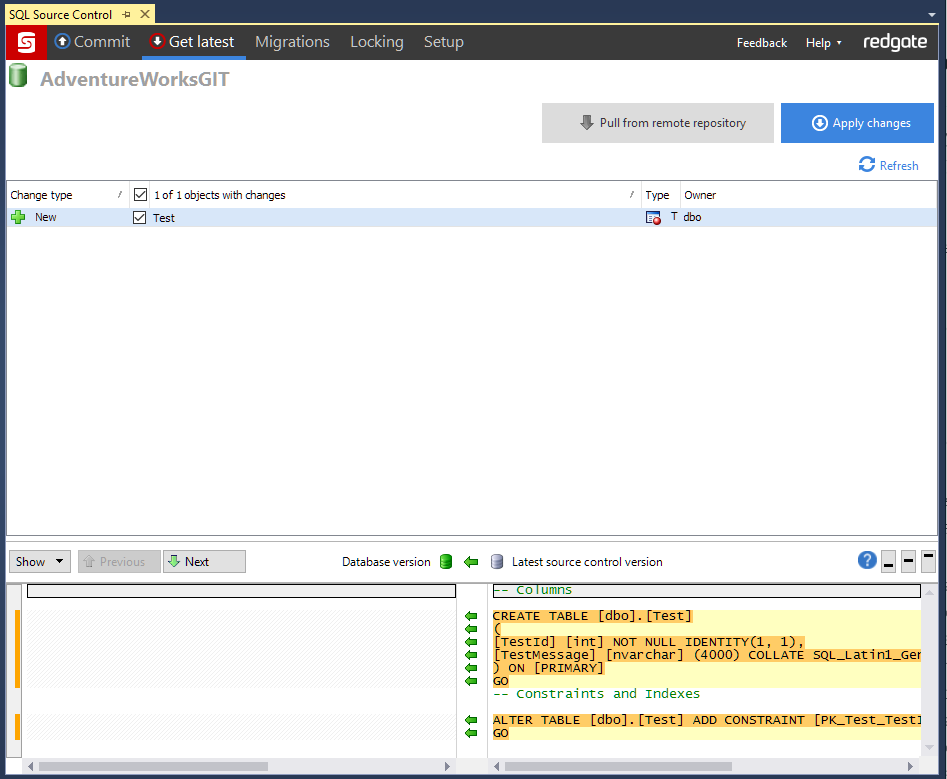
For the purposes of this demonstration, I have created a test table in the development branch called "Test." As you can see with this screen shot the test table only appears in the development database.
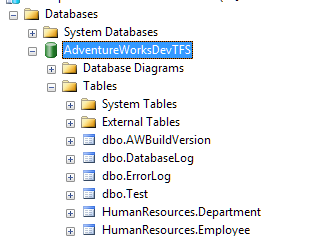
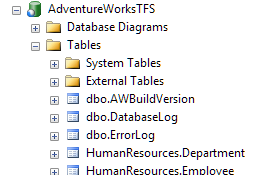
While the database for the main branch does not have the table.
Connection Strings
Connection strings are the first issue most developers run into when using a dedicated model. It doesn't matter if they have one database or a database for each branch. The majority of the projects I have worked on have stored the database connection strings in an app.config or a web.config file. I've worked on applications where the connection string is stored in a database resulting in some Inception levels of complexity, so I won't discuss those.
In later versions of .NET it is possible to point sections of a web.config or an app.config at a different file. What we did was point our connection strings section at a file called localconnections.config
<connectionStrings configSource="localconnections.config" />
The file itself only has connection strings, but they point to a local server.
<connectionStrings>
<add name="SomeEntities" connectionString="data source=LocalServer;initial catalog=LocalDatabase;integrated security=True;App=EntityFramework" providerName="System.Data.SqlClient" />
</connectionStrings>
That file is ignored in the .gitignore file
Source/*/localconnections.config
We have a transform file for the release version of the source code which will transform that over to a file checked into source control called connections.config
<connectionStrings xdt:Transform="SetAttributes(configSource)" configSource="connections.config" />
That file is the one that points to the server
<connectionStrings>
<add name="SomeEntities" connectionString="data source=ExternalServer;initial catalog=LocalDatabase;integrated security=True;App=EntityFramework" providerName="System.Data.SqlClient" />
</connectionStrings>
Merging changes between branches
No matter which version control system being used, the merging of code from a branch such as development into master, and getting the updated database changes is straightforward
- Merge the changes using the version control UI
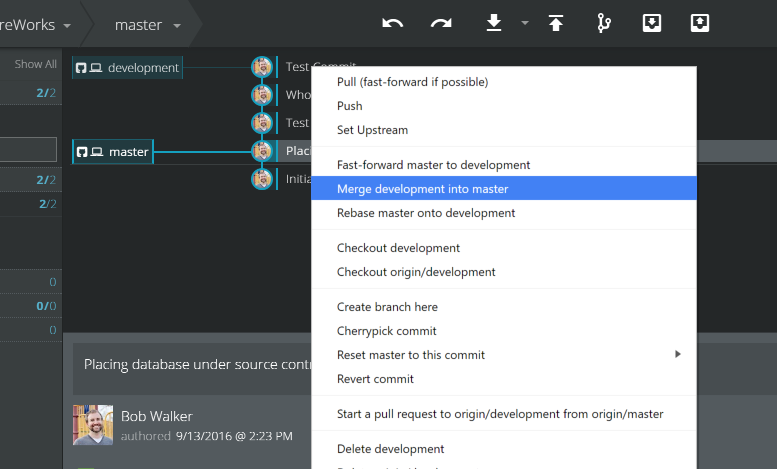
- To verify the table is not in database go ahead and expand out the table list in SSMS
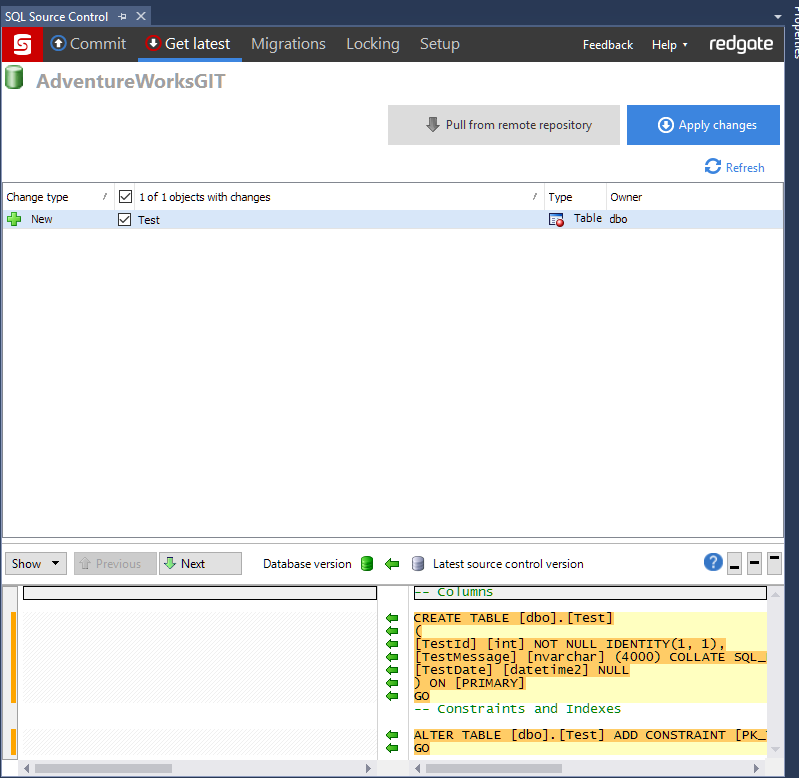
- Go to the get latest changes tab and pull down the changes from the merge
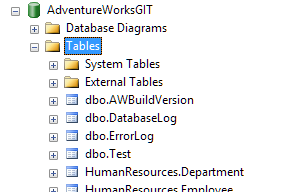
- Now the merged table will appear in the table list
This is where SQL Source Control really shines because it does a great job of picking up the new changes. Applying the changes is only a matter of clicking the button.
Conclusion
Redgate SQL Source Control with dedicated databases for each developer makes it very easy to implement a branching strategy. My team uses a modified version of GitFlow which is one of the more complex branching strategies for GIT. Most of the developers on the team have a single database locally. Right now the delta between master and development is rather small, which makes the thrashing very minimal.
What is really nice is Redgate's SQL Source Control is flexible enough to handle a lot of different version control systems. It doesn't matter if you are using TFVC, GIT, SVN or Mercurial. It also provides the flexibility to handle virtually any type of branching strategy, from Gitflow, to feature branches, to release branches, to ALM's super complex branching strategy.